Kako generativne AI platforme gutaju sve veće okeane podataka i povezuju se sa sve više i više korporativnih baza podataka, istraživači upozoravaju: alati su veoma netačni i postaju sve nedokučiviji.
Autor: Lucas Mearian
Veliki jezićki modeli (LLM – Large Language Models), algoritamske platforme na kojima su izgrađeni generativni AI (genAI) alati kao što je ChatGPT, veoma su netačni kada se povežu sa korporativnim bazama podataka i, prema dve studije, postaju manje transparentni.
Jedna studija Univerziteta Stanford pokazala je da kako LLM nastavljaju da apsorbuju ogromne količine informacija i rastu u veličini, sve je teže pratiti nastanak podataka koje koriste. To, zatim, otežava preduzećima da saznaju da li mogu bezbedno da prave aplikacije koje koriste komercijalne temeljne genAI modele, a akademicima da se u istraživanju oslanjaju na njih.
To takođe otežava zakonodavcima da osmisle logične politike za obuzdavanje moćne tehnologije, a „potrošačima da shvate ograničenja modela ili da traže obeštećenje za prouzrokovanu štetu“, navodi se u studiji Stanforda.
LLM-ovi (takođe poznati kao osnovni modeli) kao što su GPT, LLaMA i DALL-E pojavili su se tokom prošle godine i transformisali veštačku inteligenciju (AI), pružajući mnogim kompanijama koje eksperimentišu sa njima povećanje produktivnosti i efikasnosti. Ali te prednosti prati velika količina neizvesnosti.
„Transparentnost je suštinski preduslov za javnu odgovornost, naučne inovacije i efikasno upravljanje digitalnim tehnologijama“, rekao je Rishi Bommasani, vođa društva u Stenfordovom Centru za istraživanje osnovnih modela. „Nedostatak transparentnosti je dugo bio problem za potrošače digitalnih tehnologija.“
Na primer, obmanjujući onlajn oglasi i cene, nejasne prakse plaćanja u deljenju vožnje, obmanjujući obrasci koji navedu korisnike da neznajući kupuju, i bezbroj problema sa transparentnošću oko moderiranja sadržaja stvorili su ogroman ekosistem pogrešnih informacija na društvenim medijima, primećuje Bommasani.
„Kako transparentnost oko komercijalnih [osnovnih modela] slabi, suočavamo se sa sličnim vrstama pretnji po zaštitu potrošača“, rekao je on.
Na primer, OpenAI, kome se reč „otvoreno“ (engl. open) nalazi u samom nazivu, jasno je rekao da neće biti transparentan u vezi sa većinom aspekata svog vodećeg modela, GPT-4, primetili su istraživači sa Stanforda.
Za procenjivanje transparentnosti je Stanford okupio tim koji je uključivao istraživače sa MIT-a i Prinstona da dizajniraju sistem bodovanja pod nazivom Indeks transparentnosti osnovnog modela (FMTI). Ovaj sistem procenjuje 100 različitih aspekata ili indikatora transparentnosti, uključujući kako kompanija gradi temeljni model, kako on funkcioniše i kako se nakon toga koristi.
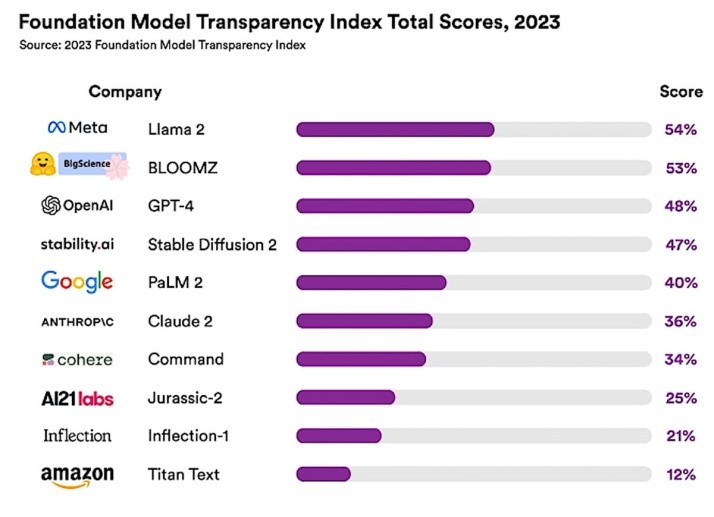
Stenfordska studija je procenila 10 LLM-a i otkrila da je srednji indeks transparentnosti bio svega 37%. LLaMA je postigao najviši rezultat, sa ocenom transparentnosti od 52%; sledili su GPT-4 i PaLM 2, koji su postigli 48%, odnosno 47%.
„Ako nemate transparentnost, upravljači ne mogu ni da postave prava pitanja, a kamoli da preduzmu mere u ovim oblastima“, rekao je Bomasani.
Za to vreme, skoro svi viši šefovi (95%) veruju da zaposleni redovno koriste genAI alatke, a više od polovine (53%) kaže da one sada upravljaju određenim poslovnim odeljenjima, prema zasebnom istraživanju koje je sproveo dobavljač sajber bezbednosti i antivirusnih programa Kasperski Lab. Ta studija je otkrila da 59% rukovodilaca sada izražava duboku zabrinutost zbog bezbednosnih rizika povezanih sa genAI koji bi mogli da ugroze osetljive informacije kompanije i dovedu do gubitka kontrole nad osnovnim poslovnim funkcijama.
„Slično kao BYOD, genAI nudi preduzećima ogromne prednosti u produktivnosti, ali dok naši nalazi otkrivaju da rukovodioci odbora jasno priznaju njegovo prisustvo u svojim organizacijama, stepen njegove upotrebe i svrha obavijeni su velom misterije“, rekao je David Emm, glavni istraživač bezbednosti kompanije Kaspersky, navodi se u saopštenju.
Problem sa LLM-ima seže dublje od same transparentnosti; ukupna tačnost modela je dovedena u pitanje skoro od trenutka kada je OpenAI objavio ChatGPT pre godinu dana.
Juan Sequeda, šef laboratorije za veštačku inteligenciju u data.world, dobavljaču platforme za katalogizaciju podataka, rekao je da je njegova kompanija testirala LLM-e povezane sa SQL bazama podataka i imala zadatak da pruži odgovore na pitanja specifična za kompaniju. Koristeći podatke osiguravajućih kompanija iz stvarnog sveta, studija data.world je pokazala da LLM-i vraćaju tačne odgovore na većinu osnovnih poslovnih upita u svega 22% slučajeva. A za upite srednjeg i stručnog nivoa, tačnost je pala na 0%.
Nedostatak odgovarajućih text-to-SQL referentnih vrednosti prilagođenih postavkama preduzeća može uticati na sposobnost LLM-a da precizno odgovore na korisnička pitanja ili „upite“.
„Smatra se da LLM-ovima nedostaje interni poslovni kontekst, što je ključno za tačnost“, rekao je Sequeda. „Naša studija pokazuje jaz kada je u pitanju korišćenje LLM-a konkretno sa SQL bazama podataka, koje su glavni izvor strukturiranih podataka u preduzeću. Pretpostavio bih da jaz postoji i za druge baze podataka.“
Preduzeća ulažu milione dolara u skladišta podataka u oblaku, poslovnu inteligenciju, alate za vizuelizaciju i ETL i ELT sisteme, sve kako bi mogla bolje da iskoriste podatke, primetio je Sequeda. Mogućnost korišćenja LLM-a za postavljanje pitanja o tim podacima otvara ogromne mogućnosti za poboljšanje procesa kao što su ključni indikatori učinka, metrike i strateško planiranje, ili kreiranje potpuno novih aplikacija koje koriste duboku ekspertizu u domenu stvaranja veće vrednosti.
Studija se prvenstveno fokusirala na odgovaranje na pitanja koristeći GPT-4, sa nultim upitima direktno na SQL baze podataka. Stopa tačnosti? Samo 16%.
Neto efekat netačnih odgovora zasnovanih na korporativnim bazama podataka je opadanje poverenja. „Šta se dešava ako odboru predstavljate brojeve koji nisu tačni? Ili finansijskoj komisiji? U svakom slučaju, cena bi bila visoka“, rekao je Sequeda.
Problem sa LLM-ovima je u tome što su oni statističke mašine i mašine za uklapanje šablona koje predviđaju sledeću reč na osnovu reči koje im prethode. Njihova predviđanja su zasnovana na posmatranju obrazaca iz čitavog sadržaja otvorenog veba. Pošto je otvoreni veb u suštini veoma veliki skup podataka, LLM će vratiti stvari koje izgledaju vrlo uverljivo, ali takođe mogu biti netačne, kaže Sequeda.
„Sledeći razlog je to što modeli samo predviđaju na osnovu obrazaca koje su videli. Šta se dešava ako nisu videli obrasce specifične za vaše preduzeće? Pa, nepreciznost se povećava“, rekao je on.
„Ako preduzeće pokuša da implementira LLM u značajnijem obimu, a ne obrati pažnju na preciznost, inicijativa će propasti“, nastavio je Sequeda. „Korisnici će uskoro otkriti da ne mogu verovati LLM-ima i prestaće da ih koriste. Videli smo sličan rezultat u podacima i analitici tokom godina.“
Tačnost LLM-a se povećala na 54% kada se pitanja postavljaju preko Knowledge Graph predstavljanja SQL baze podataka preduzeća. „Stoga, ulaganje u provajdere Knowledge Grapha omogućava veću preciznost sistema za odgovore koji su zasnovani na LLM-u“, rekao je Sequeda. „Još uvek nije jasno zašto se to dešava, jer ne znamo šta se dešava unutar LLM-a.
„Ono što znamo je da ako LLM-u date upit sa ontologijom mapiranom unutar Knowledge Grapha, koji sadrži kritični poslovni kontekst, tačnost je tri puta veća nego ako to ne učinite“, nastavio je Sequeda. „Međutim, važno je da se zapitamo, šta je to „dovoljno tačan odgovor“?“
Da bi se povećala mogućnost tačnih odgovora LLM-a, kompanije moraju da imaju „jaku osnovu podataka“, ili ono što Sequeda i drugi nazivaju podacima spremnim za veštačku inteligenciju; to znači da su podaci mapirani u Knowledge Graph da bi se povećala tačnost odgovora i da bi se osiguralo da postoji objašnjivost, „što znači da možete naterati LLM da pokaže rezultate“.
Drugi način da se poveća tačnost modela bila bi upotreba malih jezičkih modela (SLM – small languade model) ili čak modela jezika specifičnih za industriju (ILM – industry-specific language models). „Mogu da zamislim budućnost u kojoj svako preduzeće koristi određeni broj specifičnih LLM-ova, od kojih je svaki podešen za određene vrste odgovora na pitanja“, rekao je Sequeda.
„Ipak, pristup je i dalje isti: predviđanje sledeće reči. To predviđanje može biti dobro, ali uvek će postojati šansa da je predviđanje pogrešno.“
Svaka kompanija takođe treba da obezbedi nadzor i upravljanje kako bi sprečila da osetljive i vlasničke informacije budu izložene riziku od strane modela koji nisu predvidljivi, rekao je Sequeda.
Izvor: COMPUTERWORLD